1. ShardingSphere-JDBC 分库分表读写分离
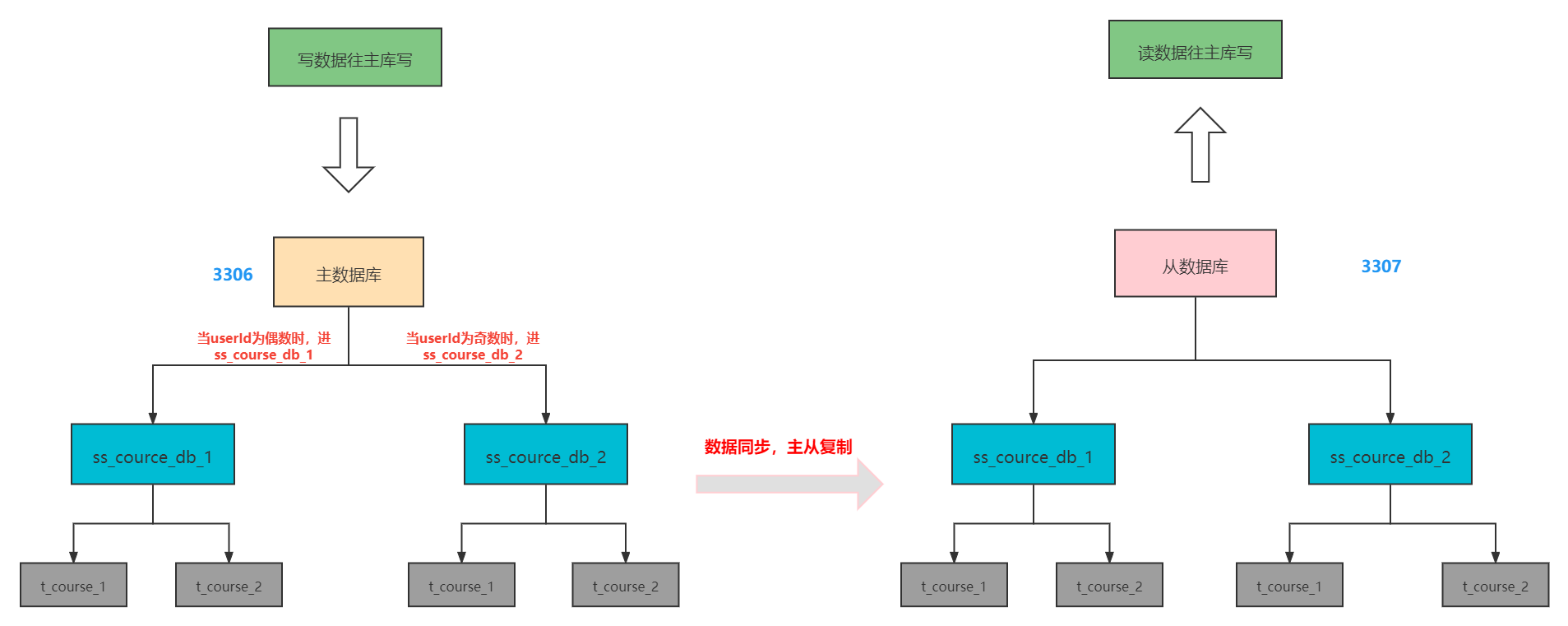
分库分表读写分离:写数据时根据userId和cid进行分库处理,读数据从从库读。
1.1 环境搭建
环境说明:
SpringBoot 2.5.7+MyBatisPlus+ShardingSphere-JDBC 5.0.0-alpha+Druid+MySQL 8.0
1.1.1 pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.13</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.0.0-alpha</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
1.1.2 创建数据库和表
按照水平分表的方式,创建数据库和数据库表
- 创建数据库:
ss_course_db_1、ss_course_db_2、ss_dict_db - 具体操作,可以参考前面两篇文章
对三个数据库都进行了主从配置,但此处只用读写分离,还不涉及分库分表,所有只涉及ss_dict_db数据库
对于配置多个数据库的主从配置,需要在MySQL的my.ini文件中,配置同步多个数据库即可,配置如下,主从配置文件都要加。
binlog-do-db=ss_dict_db
binlog-do-db=ss_course_db_1
binlog-do-db=ss_course_db_2

- 分库规则:约定
userId值偶数添加到m1库,userId是奇数添加到m2库 - 分表规则:约定
cid值偶数添加到t_course_1表,如果cid是奇数添加到t_course_2表
1.1.3 编写业务代码
此处编写业务代码略,具体代码可以下面的源码地址。代码里集成了Swagger,用于方便测试。
1.1.4 配置文件
server.port=8005
spring.shardingsphere.enabled=true
# 打开sql输出日志
spring.shardingsphere.props.sql-show=true
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1,m2,s3,s4
# 配置第一个数据源具,主数据库
spring.shardingsphere.datasource.common.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.common.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.url=jdbc:mysql://127.0.0.1:3306/ss_course_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2b8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
spring.shardingsphere.datasource.m2.url=jdbc:mysql://127.0.0.1:3306/ss_course_db_2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2b8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
# 配置第二个数据源,从数据库
spring.shardingsphere.datasource.s3.url=jdbc:mysql://127.0.0.1:3307/ss_course_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2b8
spring.shardingsphere.datasource.s3.username=root
spring.shardingsphere.datasource.s3.password=root
# 配置第二个数据源,从数据库
spring.shardingsphere.datasource.s4.url=jdbc:mysql://127.0.0.1:3307/ss_course_db_2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2b8
spring.shardingsphere.datasource.s4.username=root
spring.shardingsphere.datasource.s4.password=root
# 指定course表里面主键cid 生成策略 SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
# 指定分库策略 约定userId值偶数添加到m1库,userId是奇数添加到m2库
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=m$->{user_id%2 + 1}
# 指定分表策略 约定cid值偶数添加到t_course_1表,如果cid是奇数添加到t_course_2表
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_course_$->{cid % 2 + 1}
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=m$->{1..2}.t_course_$->{1..2}
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-name=database-inline
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-inline
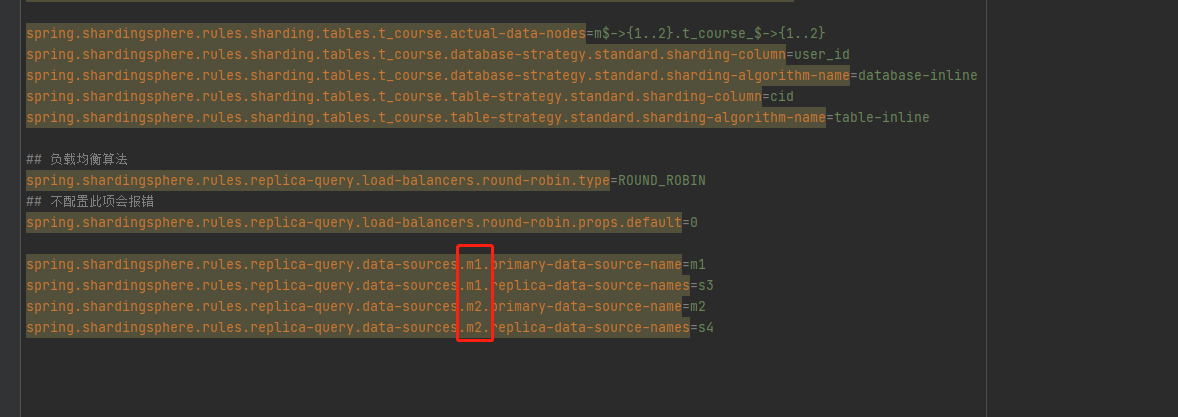
## 负载均衡算法
spring.shardingsphere.rules.replica-query.load-balancers.round-robin.type=ROUND_ROBIN
## 不配置此项会报错
spring.shardingsphere.rules.replica-query.load-balancers.round-robin.props.default=0
spring.shardingsphere.rules.replica-query.data-sources.m1.primary-data-source-name=m1
spring.shardingsphere.rules.replica-query.data-sources.m1.replica-data-source-names=s3
spring.shardingsphere.rules.replica-query.data-sources.m2.primary-data-source-name=m2
spring.shardingsphere.rules.replica-query.data-sources.m2.replica-data-source-names=s4
1.1.5 测试结果
启动程序,在浏览器输入:http://localhost:8005/swagger-ui.html
初始时数据:3306为主库,3307为从库
主数据库数据:
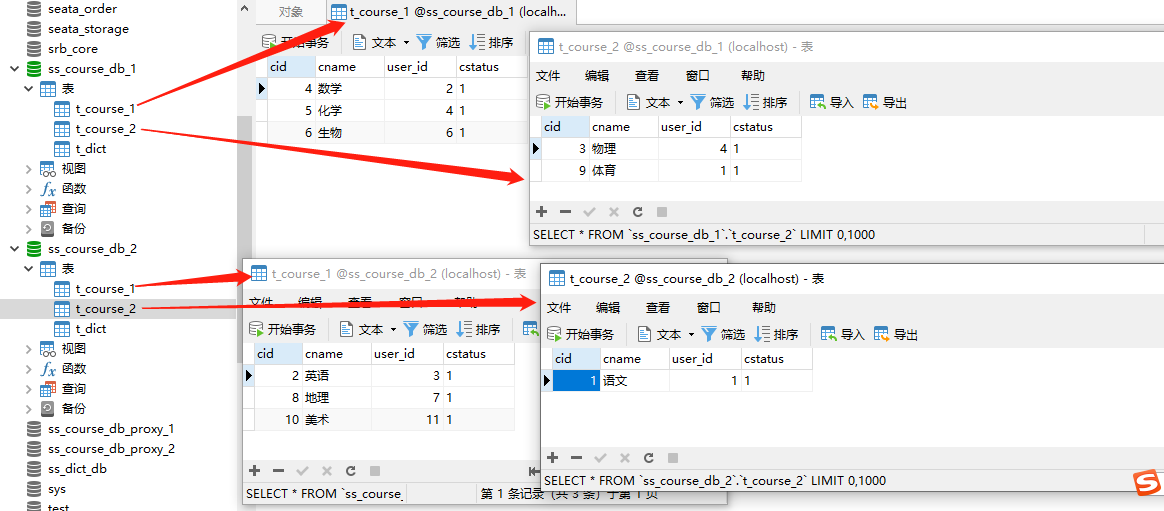
从数据库数据

添加数据
再来说下分库分表规则:
- 分库规则:约定
userId值偶数添加到m1库,userId是奇数添加到m2库 - 分表规则:约定
cid值偶数添加到t_course_1表,如果cid是奇数添加到t_course_2表

查看数据库表数据
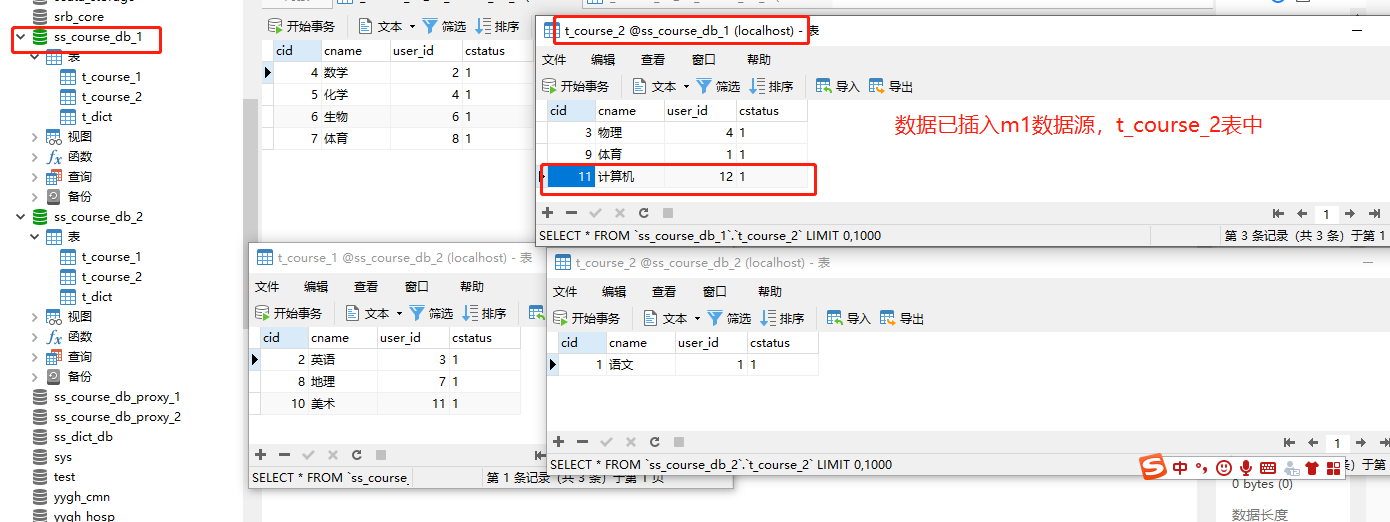
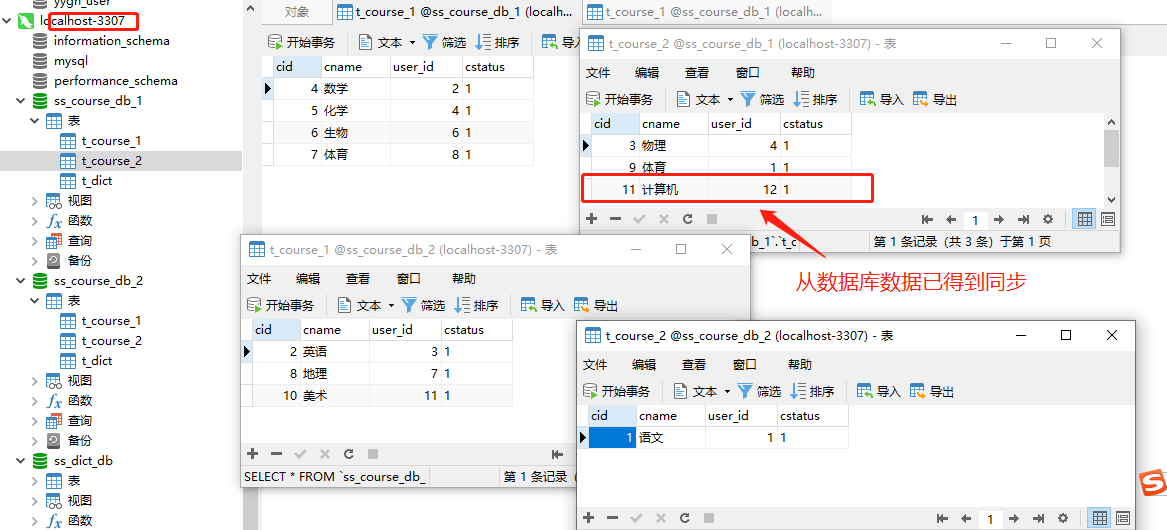
查看所有数据
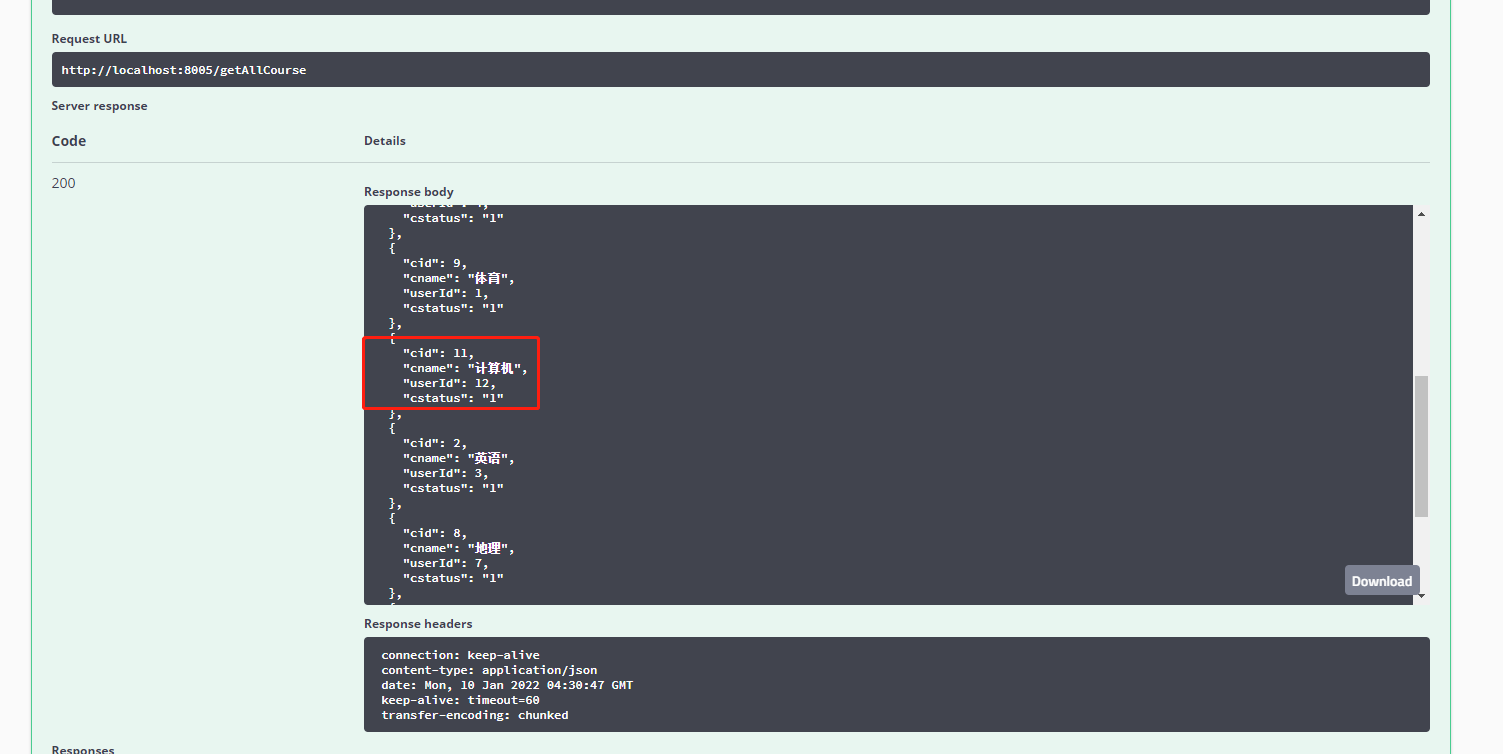
日志显示,从m3,m4数据源查询,即3307从数据库。

2. 说明
源码地址:https://github.com/Hofanking/springboot-shardingsphere-example
源代码目录结构说明:
springboot-shardingsphere-example
|— shardingsphere-database (分库分表)
|— shardingsphere-database-table-write-read (分库分表读写分离)
|— shardingsphere-proxy-table (使用proxy分表)
|— shardingsphere-public (公共表)
|— shardingsphere-table (分表)
|— shardingsphere-write-read (读写分离)
3.坑
在上一篇中,配置读写分离时,<replica-query-data-source-name>配置成对应的数据源,根本不会成功,而是要写成prds。
但在此处,配置成对应的数据源却可以成功,真的很神奇!
4. ShardingSphere-JDBC 小结
Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。
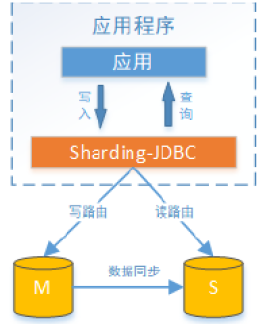
Sharding-JDBC提供一主多从的读写分离配置,可独立使用,也可配合分库分表使用,同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。Sharding-JDBC不提供主从数据库的数据同步功能,需要采用其他机制支持。
--end--